Enabling Full Cycle Development: 4 Cloud Native Platform Capabilities


Full Cycle Developers: More Feedback, Faster
Platform Teams: Remove Friction, Add Safety
Four Core Cloud Platform Capabilities
Avoiding Platform Antipatterns
Next Steps
Cloud computing and container orchestration frameworks provide an excellent foundation for deploying and running modern software applications. However, in order for these technologies to support the move towards "full cycle development" -- where developers take increased ownership from idea to delivery -- there are several requirements that must be met for both the development and platform/SRE personas. Many teams design and build a platform in order to support these requirements, often using Kubernetes as a foundation. This platform must focus on offering self-service functionality, and it must support four core capabilities: container management, progressive delivery, edge management, and observability.
In part one of this series we covered the topic of "Why Cloud Native?" in detail. This article will explore the new dev/ops requirements, outline the four core platform capabilities, and provide guidance on avoiding common antipatterns when building an application platform.
Full Cycle Developers: More Feedback, Faster
When adopting a cloud native approach, developers need to be able to run through the entire SDLC independently. And they need to do this with speed and with confidence that they are adding value to end-users (and not causing any unintended negative impacts). Developers want to build and package applications within containers, and rely only on self-service interfaces and automation (provided by the platform team) to test, deploy, release, run, and observe applications in production.
This rapid feedback loop supports developers in becoming more customer-focused. This enables more functionality to be delivered, with the goal of providing more verifiable value to end users in a repeatable manner.
Platform Teams: Remove Friction, Add Safety
Platform teams need to capable of providing three primary functions:
- Removing friction from packaging applications into containers, and from deploying and releasing functionality.
- Enabling the observation of system behaviour, and setting sane defaults and alerts that prevent unexpected functionality within the platform from causing cascading failure.
- Assisting the organisation to understand and meet security and regulatory requirements.
The foundational goals of continuous delivery are focused on being able to deliver functionality to end users in a manner that is as fast and as stable as the business requires. Creating a supportive platform is vital to this, and so is creating an effective developer experience (DevEx) for interacting with the platform via tools and APIs.
Four Core Cloud Platform Capabilities
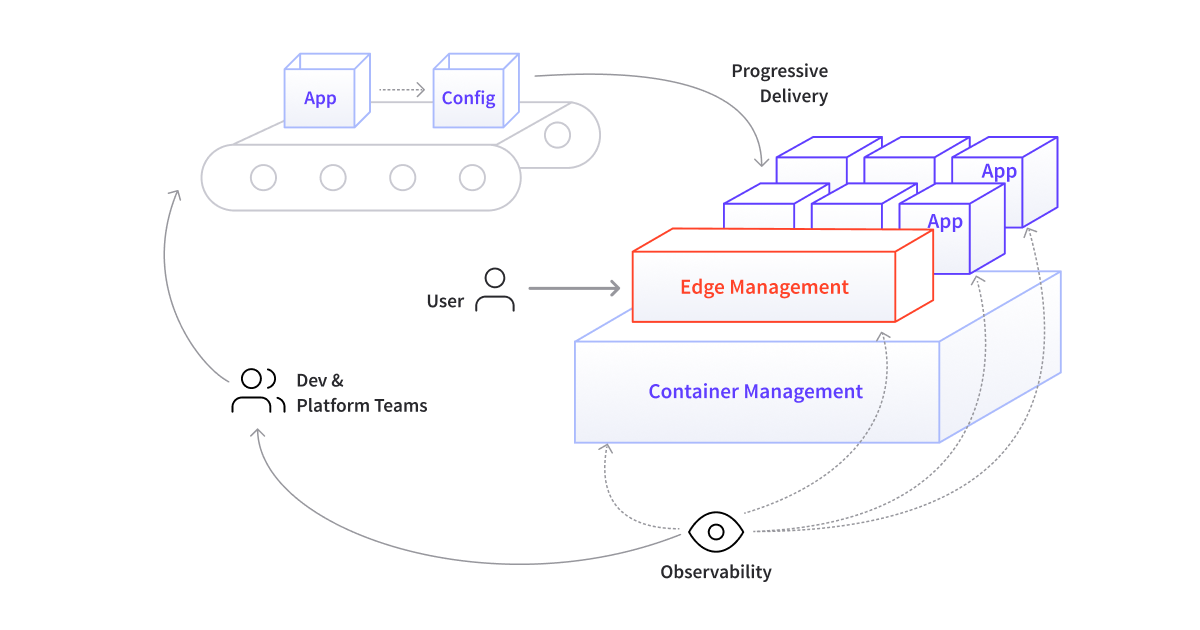
Bringing together all of the requirements discussed so far results in four core capabilities that a cloud native platform must provide: container management, progressive delivery, edge management, and observability management.
Container Management
This is the ability to manage and run container-based applications at scale and on a variety of infrastructures. Developers should be able to perform these operations in a self-service manner that can easily be automated and observed. This capability must also allow the platform team to set policies around access, control, and auditability.
Progressive Delivery
This capability is focused on supporting the creation of pipelines that enable the automated build, verification, deployment, release, and observability of applications by developers. This capability should also support platform teams in centralizing the codification and verification of quality and security properties.
Edge Management
Effective edge management should enable the self-service release of new functionality by developers. It should also support centralized configuration of sane defaults, such as TLS enforcement and rate limiting for DDoS protection, and the decentralized configuration of other cross functional requirements associated with traffic management, such as authn/z, retries, and circuit breaking.
Observability
This capability should support the collection and analysis of end user and application feedback directly by developers and the platform team. This allows product teams to iterate against business goals and KPIs, and supports the platform team in observing and managing infrastructure and ensuring their service level objectives (SLOs) are met.
Avoiding Platform Antipatterns
At first glance, providing a platform that provides all of the four capabilities may appear relatively simple. However, there are a number of platform antipatterns which have been discovered over the recent history of software development. Whether an organisation buys a cloud native platform or builds this one sprint at a time, there are a number of common mistakes that must be avoided.
Centralized Design and Ownership: One Size Doesn’t Fit All
Many early attempts at creating a platform within an organization were driven by a single operations team without collaboration with the development teams. The ownership of these platforms tended to be centralised, the design work done upfront, and the resulting platforms were typically monolithic in operation. In order to use the platform, developers had to communicate with the operations team via tickets to get anything done, e.g. deploy artifact X, open port Y, and enable route Z.
These platforms often only supported limited “core” use cases that were identified as part of the upfront design process. Problems often emerged when developers wanted to design and deploy more modular systems, or implement new communication protocols. For example, as developers embraced the microservices architectural style, they frequently exposed more APIs at the edge of the system. They also adopted multiple protocols for applications: REST-like interactions for resource manipulations operations, WebSockets for streaming data, and gRPC for low-latency RPC calls
As developers moved away from the one-size-fits-all specifications, this increasingly meant raising more and more tickets for the operations team. The combination of the high cost of handoffs and the frequently inadequate (or slowing changing) platform meant that developers could not release software at the speed that the business required. Often this led to development teams taking matters into their own hands.
Fragmented Platform Implementation
The failure of the centralized platform design and ownership model led to a swing in the opposite direction. Independent service development teams began building their own micro-platforms. This often manifested itself with coarse-grained access points being exposed at the edge of the system that forwarded all end-user requests to one of several development team-managed reverse proxies or API gateways. Developers had full control over these endpoints. However, inter-team collaboration was often low. Individual services were often configured to use third-party authentication and authorization services, leading to authentication sprawl. The capability to support availability and reliability goals were implemented in an ad hoc manner via language-specific libraries.
This failure mode led to lots of teams reinventing the (subtly different) wheel. Even popular open source libraries, such as Netflix’s Hystrix circuit-breaker, were reimplemented subtly differently across various language platforms. The fragmentation meant that it was difficult to ensure consistency of availability, reliability, and security. And because all of these features were baked-into each application, each team had to use a different workflow to deploy, test, and observe their applications. This lack of common developer experience often caused additional challenges.
Slow Development Loops: Less Time Coding, More Time Toiling
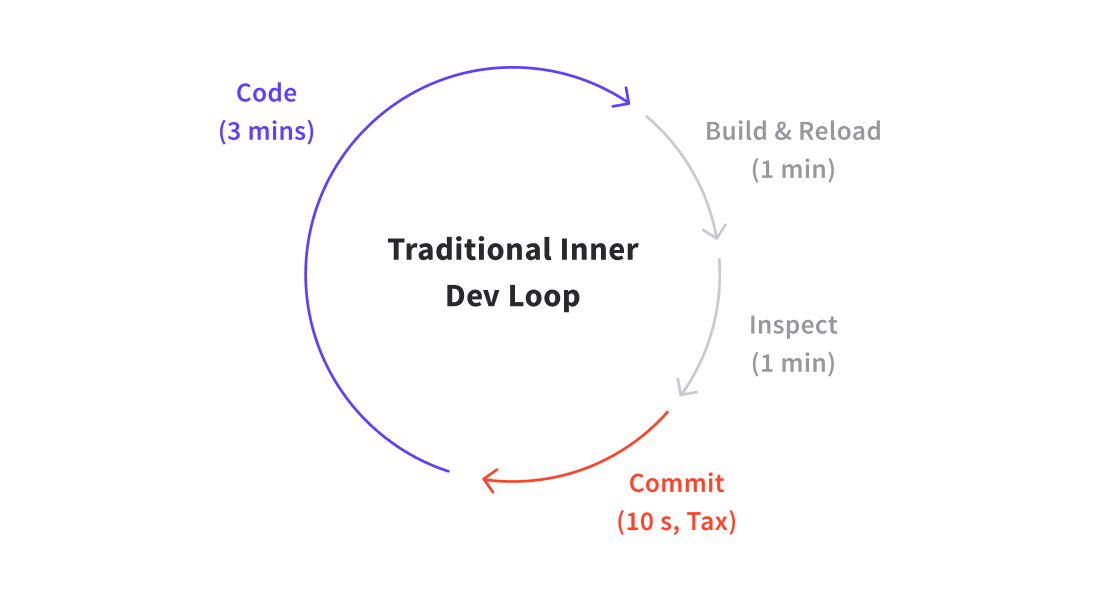
Cloud native technologies also fundamentally altered the developer experience. Not only are engineers now expected to design and build distributed service-based applications, but their entire development loop has been disrupted. No longer can developers rely on monolithic application development best practices, such as checking out the entire codebase and coding locally with a rapid “live-reload” inner developer loop. They now have to manage external dependencies, build containers, and implement orchestration configuration (e.g. Kubernetes YAML). This may appear trivial at first glance, but this has a large impact on development time.
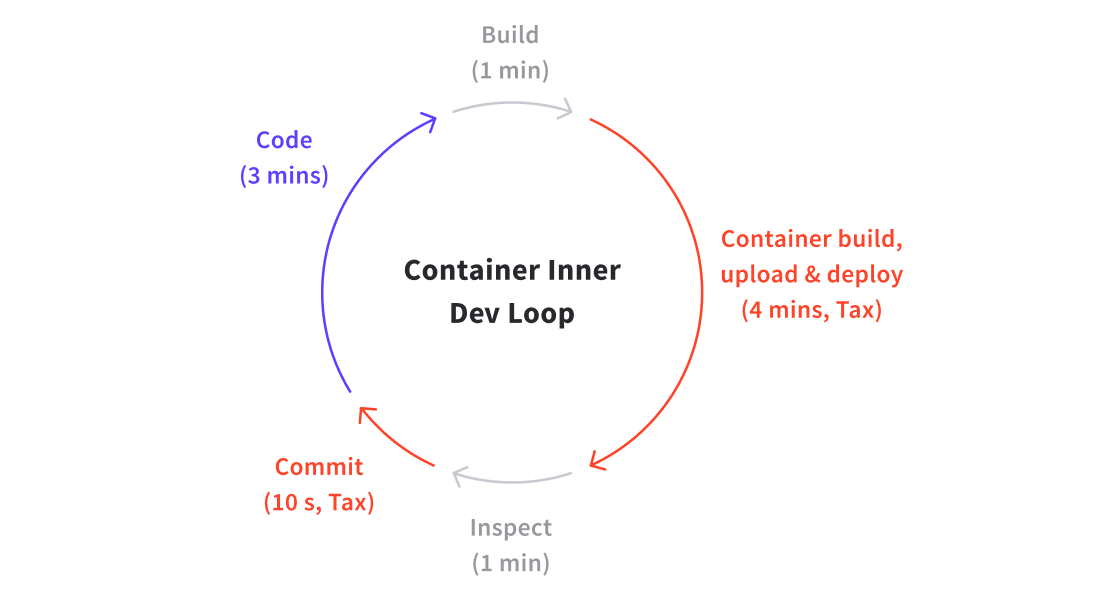
If a typical developer codes for 360 minutes (6 hours) a day, with a traditional local iterative development loop of 5 minutes -- 3 coding, 1 building i.e. compiling/deploying/reloading, 1 testing inspecting, and 10-20 seconds for committing code -- they can expect to make ~70 iterations of their code per day. Any one of these iterations could be a release candidate. The only “developer tax” being paid here is for the commit process, which is negligible.
If the build time is incremented to 5 minutes -- not atypical with a standard container build, registry upload, and deploy -- then the number of possible development iterations per day drops to ~40. At the extreme that’s a 40% decrease in potential new features being released. This new container build step is a hidden tax, which is quite expensive.
Many development teams began using custom proxies to either automatically and continually sync their local development code base with a remote surrogate (enabling “live reload” in a remote cluster), or route all remote service traffic to their local services for testing. The former approach had limited value for compiled languages, and the latter often did not support collaboration within teams where multiple users want to work on the same services.
In addition to the challenges with the inner development loop, the changing outer development loop also caused issues. Over the past 20 years, end users and customers have become more demanding, but also less sure of their requirements. Pioneered by disruptive organizations like Netflix, Spotify, and Google, this has resulted in software delivery teams needing to be capable of rapidly delivering experiments into production. Unit, integration, and component testing is still vitally important, but modern application platforms must also support the incremental release of functionality and applications to end users in order to allow testing in production.
The traditional outer development loop for software engineers of code merge, code review, build artifact, test execution, and deploy has now evolved. A typical modern outer loop now consists of code merge, automated code review, build artifact and container, test execution, deployment, controlled (canary) release, and observation of results. If a developer doesn’t have access to self-service configuration of the release then the time taken for this outer loop increases by at least an order of magnitude e.g. 1 minute to deploy an updated canary release routing configuration versus 10 minutes to raise a ticket for a route to be modified via the platform team.
Next Steps
With the motivations for enabling full cycle development presented, the four capabilities of a cloud native platform defined, and a number of antipatterns highlighted, what is next? The answer is designing and building an effective platform to support the teams and workflow. For an organization that is moving to cloud, this platform is likely to be based on a technology that has fast become the de facto vendor-agnostic computing abstraction: Kubernetes.
To learn more about enabling these shifts at your organisation, click here to download our whitepaper "4 Essential Elements of Kubernetes Platform". You can also subscribe below to get these articles and more delivered to your inbox!