Cloud Native Workflows, GitOps, and Kubernetes

The biggest change when adopting Kubernetes
Centralized vs decentralized development
The cloud-native software development lifecycle
Strategies for cloud-native software development
Summary
The biggest change when adopting Kubernetes
Much of the discussion about Kubernetes and microservices focuses on the changes in architecture: gRPC vs HTTP, service mesh (or not), observability, and so on. The official CNCF Cloud-Native definition echoes this bias:
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
While these changes are significant, this technological view of cloud-native sidesteps the fundamental change as organizations become cloud-native.
Cloud-native is a fundamental shift in software development workflow.
Centralized vs decentralized development
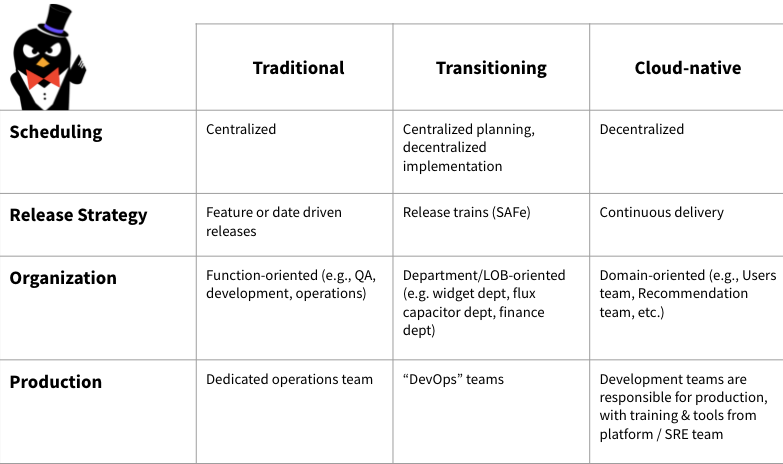
The traditional software development model is highly centralized. A single central application is released on a predictable schedule. This application and schedule serves as the synchronization point for every engineer in the organization. The application goes through a defined set of phases: development, code freeze, QA, user verification testing, release. Thus the entire application is in the same phase at any moment in time.
Cloud native development is decentralized. There is no central application, nor is there a centralized release schedule. Individual development teams own microservices. These microservices go through the different phases of a software development cycle independently. As a consequence, at any moment in time, the entire application is simultaneously in multiple phases of development.
The cloud-native software development lifecycle
The decentralized development model has enormous implications for all aspects of the cloud native software development lifecycle. In the centralized development model, there is a single artifact -- the application -- that can be replicated and managed throughout the software development lifecycle. Now, that application has been replaced with a constantly changing set of microservices.
In this model:
- The application is always in flux, as new versions of a service are released
- A centralized ownership model doesn’t exist, since there is no central application
How does this impact the actual software development lifecycle?
Strategies for cloud-native software development
Over the past few years, a common set of strategies and best practices have emerged for adapting to the new cloud-native software development lifecycle. Practitioners of these approaches fall into two categories: application developers, who build microservices, and platform engineers, who build and maintain infrastructure to support application developers.
Development
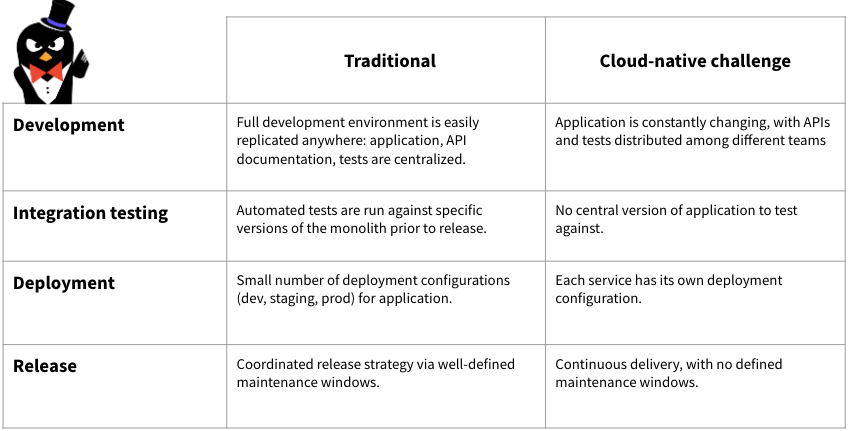
Cloud native applications are difficult to replicate: multiple microservices, constant updates, and, increasingly, involve a heterogeneous mix of technologies. This complexity, if not properly managed, can create an enormous drag on developer productivity.
Developers need to be able to quickly create a development environment and use the development environment to quickly code and test changes. On-demand packaged development environments based on Helm charts and buildpacks are common approaches to creating a development environment. This approach is then coupled with Kubernetes-specific workflow automation solutions such as Draft, Garden, Skaffold, Telepresence, and Tilt.
Microservices are increasingly heterogeneous in architecture as an application grows. Different languages (e.g., NodeJS for front-end services, with Golang for back-end services) are common. Some services may use a SQL database for persistence, while others may rely on a messaging systems such as Kafka. Services may communicate in different protocols: gRPC, HTTP, WebSockets. Discovering the available APIs for a given service in this environment is a challenge. A developer portal that discovers and publishes API documentation for different microservices becomes essential for development.
Testing
Cloud-native applications, as a moving target, introduce new challenges for testing. With a moving target, setting up a test environment is difficult -- and once set up, an environment quickly becomes outdated.
Mocks and service virtualization are techniques that help users emulate services without deploying the full service in an environment. These approaches simplify test environment setup, and can be used by unit and integration tests to provide an initial level of confidence in software quality. CNCF projects such as Telepresence can help in this area.
However, the changing nature of cloud-native applications makes it impossible to completely test microservices before release. This reality has led to the growing adoption of progressive delivery. With progressive delivery, updates are gradually released to production and tested with real user traffic for functional verification or synthetic traffic for regression and performance verification. This minimizes the blast radius of any failure.
Deployment
Traditionally, operations teams are responsible for deployment. The development team writes code and hands off an artifact to the operations team. When an application consists of dozens or hundreds of services, this approach is no longer practical. Operations teams are not staffed to deploy and run a multitude of heterogeneous services. Instead, application development teams assume responsibility for the deployment of their respective services.
GitOps is a best practice for application delivery that relies on using Git as the source of truth for the entire state of an application, including its deployment configuration. GitOps builds on the declarative configuration system built into Kubernetes itself and uses a continuous integration pipeline or in-cluster operator to synchronize the state of the environment with the declared state. By adopting GitOps, application development teams can assume responsibility for operations using a workflow they already understand (Git, pull requests).
Release
Release is frequently conflated with deployment. With cloud native applications, separating deployment and release is critical. Deployment is the actual process of getting a service running in a particular environment (e.g., production), while release is the process of moving production traffic to the new version of a service.
The constantly changing nature of the production application makes it impossible for pre-production testing to discover every possible failure mode prior to release. Thus, cloud-native application workflows adopt progressive delivery, observability, and resilience engineering as core strategies.
With progressive delivery, traffic is incrementally shifted to a new version. Building a observable system where the core properties of the application can be observed is critical to quickly identifying and troubleshooting any issues that arise while traffic is being shifted. Finally, engineering for resilience using techniques such as circuit breaking, timeouts, and automatic retries to protect the overall application from total failure in the event of a partial failure of an update is important. Together, these techniques enable the rapid and safe release of new versions of a service, while mitigating the impact of any failure.
Summary
Cloud native applications present major challenges for existing development workflows. At the same time, cloud-native workflows create new opportunities to accelerate development and agility. Careful consideration of the software development workflow is critical to the successful adoption of cloud native applications.