Resilience for distributed systems

Resilience Strategies
Load Balancing
Load Balancing Algorithms
Timeouts and Automatic Retries
Deadlines
Circuit Breakers
Implementing Resilience Strategies with Libraries
Implementing Resilience Strategies with Proxies
A cloud native app architecture that is composed of a number of microservices working together forms a distributed system. Ensuring the distributed system is available--reducing its downtime--necessitates increasing the system’s resilience. Resilience is the use of strategies for improving availability. Examples of resilience strategies include load balancing, timeouts and automatic retries, deadlines, and circuit breakers.
Resilience can be added to the distributed system in more than one way. For example, having each microservice’s code include calls to code libraries with resilience functions, or having special network proxies handle microservice requests and replies. The ultimate goal of resilience is to ensure that failures or degradations of particular microservice instances don’t cause cascading failures that cause downtime for the entire distributed system.
In the context of a distributed system, resilience is about the distributed system being capable of automatically adapting when adverse situations occur in order to continue to serve its purpose.
The terms “availability” and “resilience” have different meanings. Availability is the percentage of time that a distributed system is up. Resilience is the use of strategies for improving a distributed system’s availability.
One of the primary goals of resilience is to prevent situations where an issue with one microservice instance causes more issues, which escalate and eventually lead to distributed system failure. This is known as a cascading failure.
Resilience Strategies
Resilience strategies for distributed systems are usually employed at multiple layers of the OSI model, which is shown in the graphic. For example, the physical and data link layers (layers 1 and 2) involve physical network components, like connectivity to the Internet, so the data center and cloud service providers would be responsible for selecting and implementing resilience strategies for those layers.
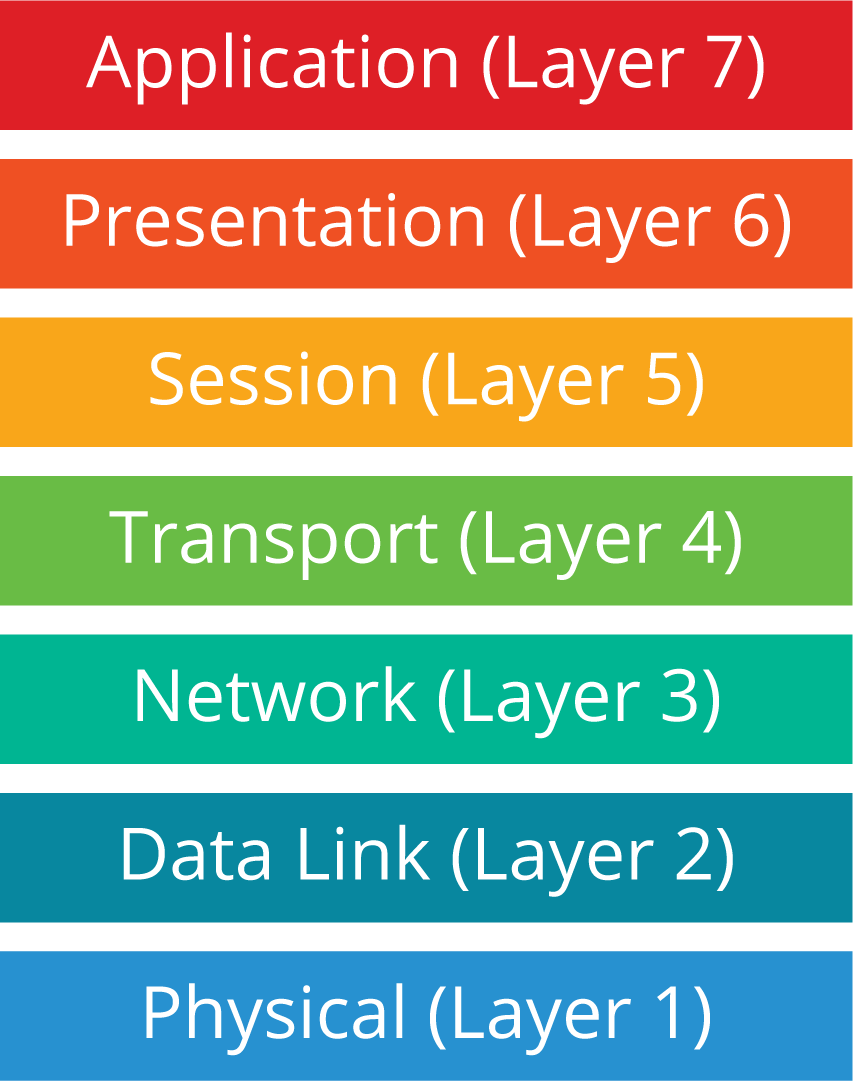
The application layer is where applications reside; this is the layer that human users (as well as other applications) directly interact with. Application-level (layer 7) resilience strategies are built into the microservices themselves. An organization’s developers could design and code an app so it will continue to work in a degraded state, providing vital functions, even when other functions have failed due to bugs, compromises, or other issues with one or more of the microservices.
An example of this type of functionality can be seen within the recommendations functionality on popular video streaming applications. Most of the time the home page contains personalized recommendations, but if the associated backend components fail, a series of generic recommendations are shown instead. This failure does not impact your ability to search for and play a video.
The transport layer (layer 4) provides network communication capabilities, like ensuring reliable delivery of communications. Network-level resilience strategies work at layer 4 to monitor the network performance of deployed instances of each microservice, and they direct requests for microservice usage to the best instances. For example, if a particular microservice instance stops responding to requests because of a failure at its location (say, a network outage), new requests would automatically be directed to other instances of that microservice.
An organization deploying a cloud-native app as a distributed system should consider resilience strategies at the network and/or application levels. Here, we’ll examine four such types of strategies for cloud-native apps:
- Load balancing
- Timeouts and automatic retries
- Deadlines
- Circuit breakers
Load balancing, timeouts, and automatic retries support redundancy for the components of the distributed system. Deadlines and circuit breakers help reduce the effect of a degradation or failure of any part of the distributed system.
Load Balancing
Load balancing for cloud native apps can be performed at multiple layers of the OSI model. Like the resilience strategies we just discussed, load balancing can be performed at layer 4 (the network or connection level) or layer 7 (the application level).
For Kubernetes, layer 4 load balancing is by default implemented using kube-proxy. It balances the load at a network connection level. The management of Pod IP addresses and routing of traffic between virtual/physical network adapters is handled via the Container Networking Interface (CNI) implementation or an overlay network, such as Calico or Weave Net.
Returning to layer 4 load balancing, suppose that one network connection is sending a million requests per second to an app, and another network connection is sending one request per second to the same app. The load balancer is not aware of this difference; it simply sees two connections. If it sent the first connection to one microservice instance and the second connection to a second microservice instance, it would consider the load to be balanced.
Layer 7 load balancing is based on the requests themselves, not the connections. A layer 7 load balancer can see the requests within the connections and send each request to the optimal microservice instance, which can provide better balancing than a layer 4 load balancer can. In general, we mean layer 7 load balancing when we say “load balancing.” Also, while layer 7 load balancing can be applied to services or microservices, here we focus on applying it to microservices only.
For cloud native apps, load balancing refers to balancing the app’s requests amongst the running instances of the microservices. Load balancing assumes there’s more than one instance of each microservice; having multiple instances of each provides redundancy. Whenever feasible, the instances are distributed so if a particular server or even site goes down, not all instances of any microservice will become unavailable.
Ideally there should be enough instances of each microservice so that even when failures occur, like site outages, there are still enough instances of each microservice available that the distributed system continues to function properly for all who need it at that time.
Load Balancing Algorithms
There are many algorithms for performing load balancing. Let’s take a closer look at three of them.
- Round robin is the simplest algorithm. The instances of each microservice take turns handling requests. For example, if microservice A has three instances--1, 2, and 3--the first request would go to instance 1, the second to instance 2, and the third to instance 3. Once each microservice has received a request, the next request would be assigned to instance 1 to start another cycle through the instances.
- Least request is a load balancing algorithm that distributes a new request to the microservice instance that has the fewest requests pending at the time. For example, suppose microservice B has four instances, and instances 1, 2, and 3 are each handling 10 requests right now but instance 4 is only handling two requests. With a least request algorithm, the next request would go to instance 4.
- Session affinity, also known as sticky sessions, is an algorithm that attempts to send all requests within a session to the same microservice instances. For example, if user Z is using an app and that causes a request to be sent to instance 1 of microservice C, then all other requests for microservice C in that same user session will be directed to instance 1.
There are numerous variants of these algorithms--for example, weighting is often added to round robin and least request algorithms so that some microservice instances receive a larger or smaller share of the requests than others. For example, you might want to favor microservice instances that typically process requests more quickly than others.
In practice, load balancing algorithms alone often don’t provide enough resilience. For example, they will continue to send requests to microservice instances that have failed and no longer respond to requests. This is where adding strategies like timeouts and automatic retries can be beneficial.
Timeouts and Automatic Retries
Timeouts are a fundamental concept for any distributed system. If one part of the system makes a request and another part fails to handle that request in a certain period of time, the request times out. The requester can then automatically retry the request with a redundant instance of the failed part of the system.
For microservices, timeouts are established and enforced between two microservices. If an instance of microservice A makes a request to an instance of microservice B and the microservice B instance doesn’t handle it in time, the request times out. The microservice A instance can then automatically retry the request with a different instance of microservice B.
There’s no guarantee that retrying a request after a timeout will succeed. For example, if all instances of microservice B have the same issue, a request to any of them might fail. But if only some instances are affected--for example, an outage at one data center--then the retry is likely to succeed.
Also, requests shouldn’t always be automatically retried. A common reason is to avoid accidentally duplicating a transaction that has already succeeded. Suppose that a request from microservice A to microservice B was successfully processed by B, but its reply to A was delayed or lost. It’s fine to reissue this request in some cases, but not in others.
- A safe transaction is one where the same request causes the same result. This is similar to a GET request in HTTP. A GET is a safe transaction because it retrieves data from a server but does not cause the data on the server to be altered. Reading the same data more than once is safe, so reissuing a request for a safe transaction should be fine. Safe transactions are also called idempotent transactions.
- An unsafe transaction is one where the same request causes a different result. For example, in HTTP, POST and PUT requests are potentially unsafe transactions because they send data to a server. Duplicating a request could cause the server to receive that data more than once and potentially process it more than once. If the transaction is authorizing a payment or an order, you certainly don’t want to have it happen too many times.
Deadlines
In addition to timeouts, distributed systems have what are called distributed timeouts or, more commonly, deadlines. These involve more than two parts of the system. Suppose there are four microservices that rely on each other: A sends a request to B, which processes it and sends its own request to C, which processes it and sends a request to D. The replies flow the other way, from D to C, C to B, and B to A.
The figure below depicts this scenario. Suppose that microservice A needs a reply to its request within 2.0 seconds. With a deadline, the time remaining to fulfill the request travels with the intermediate requests. This enables each microservice to prioritize the processing of each request it receives, and when it contacts the next microservice it will inform that microservice how much time is remaining.

Circuit Breakers
Timeouts and deadlines address each request and reply within the distributed system individually. Circuit breakers have more of a “big picture” view of the distributed system. If a particular instance of a microservice is not replying to requests or is replying to them more slowly than expected, the circuit breaker can cause subsequent requests to be sent to other instances.
A circuit breaker works by setting a limit for the degree of service degradation or failures for a single instance of a microservice. When an instance exceeds that level, this trips the circuit breaker and causes the microservice instance to stop being used temporarily.
The goal of a circuit breaker is to prevent an issue with one microservice instance from negatively affecting other microservices and potentially causing a cascading failure. Once the issue has been resolved, the microservice instance can be used again.
Cascading failures often start because of automatic retries directed at microservice instances experiencing degradation or failure. Suppose you have a microservice instance that’s overwhelmed with requests, causing it to reply slowly. If a circuit breaker detects this and temporarily stops new requests from going to the instance, the instance has a chance to catch up on its requests and recover.
But if a circuit breaker doesn’t act and new requests keep going to the instance, that instance may completely fail. That forces all the requests to go to other instances. If those instances were already near capacity, the new requests may overwhelm them too and eventually cause them to fail. This cycle continues and eventually the entire distributed system fails.
Implementing Resilience Strategies with Libraries
So far we’ve talked about several resilience strategies, including three forms of load balancing plus timeouts and automatic retries, deadlines, and circuit breakers. Now it’s time to start thinking about how these strategies can be implemented.
When microservices were first being deployed, the most common way to implement resilience strategies was to have each microservice use a standard library that supported one or more of the strategies. An example was Hystrix, an open source library that added resilience features to distributed systems. Developed by Netflix until 2018, Hystrix calls could be wrapped around any call within a microservice that relied on a request to another microservice. Another example of a resilience library is Resilience4j, which is intended for use in functional programming with Java.
Implementing resilience strategies through application libraries can certainly be viable, but it doesn’t work for every situation. Resilience libraries are language-specific and microservice developers typically use the best language for each microservice, so a resilience library might not support all the necessary languages. In order to use the resilience library, developers might have to write some microservices in languages that provide less-than-desirable performance or have other significant shortcomings.
Another concern is that relying on libraries means adding call wrappers to every susceptible call in every microservice. Some calls might be missed, some wrappers might contain errors--and having all the developers of all the microservices do things consistently is a challenge. There are also maintenance issues--every new developer who works on the microservices in the future will have to be aware of the call wrappers.
Implementing Resilience Strategies with Proxies
Over time, library-based implementations of resilience strategies have been supplanted by proxy-based implementations.
Generally speaking, a proxy sits in the middle of communications between two parties and provides some sort of service for those communications. Proxies often provide some degree of separation between the two parties. For example, party A makes a request to party B, but that request actually goes from A to the proxy, which processes the request and sends its own request to B. A and B don’t directly communicate with each other.
The figure below shows an example of this flow of communications. One session is happening between an instance of microservice A and its proxy, and a separate session is happening between A’s proxy and an instance of microservice B. The A-to-proxy and proxy-to-B sessions collectively provide the communications between A and B.
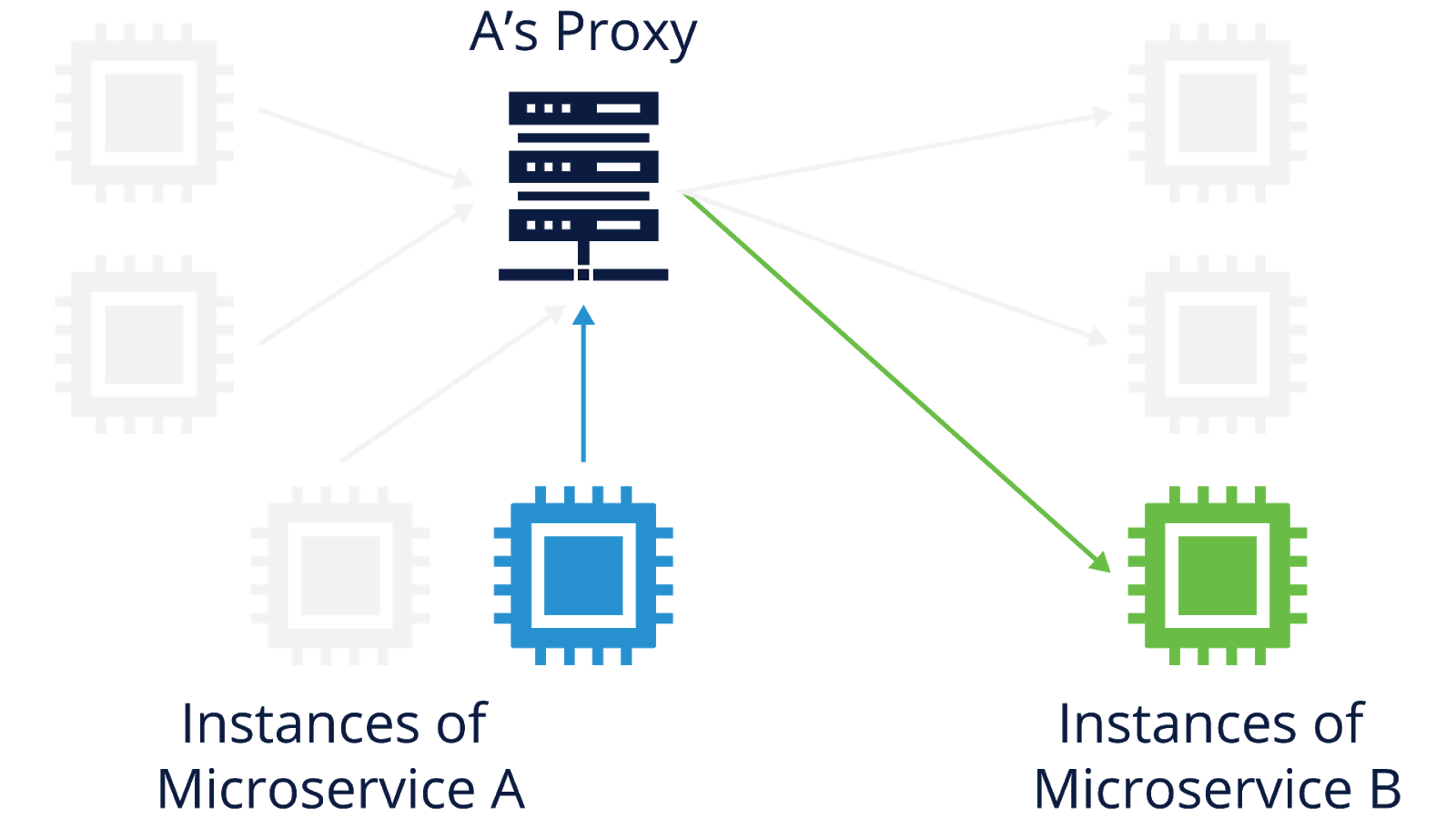
In distributed systems, proxies can implement resilience strategies between the instances of microservices. To continue the previous example, when an instance of microservice A sends a request to microservice B, that request actually goes to a proxy. The proxy would process A’s request and decide which instance of microservice B it should go to, and then it would issue the request on A’s behalf.
The proxy would monitor for a reply from the B instance, and if the reply was not received in a timely manner, it could automatically retry the request with a different microservice B instance. In the figure, the proxy for microservice A has three instances of microservice B to choose from, and it selects the third one. If the third one does not respond quickly enough, the proxy can use the first or second instance instead.
The primary advantage of proxy-based resilience is that the individual microservices do not need to be modified to use special libraries; any microservices can be proxied.