Edge Stack
Simplify and secure your Kubernetes application development with best-in-class, cloud-native API Gateway solution



Trusted By Developers At




Why Edge Stack API Gateway
Flexible Kubernetes Management
Flexible Kubernetes management with Ingress Controller
Simplified Traffic Management
Simplified traffic management to ensure high availability, resilience and uptime.
Decentralized
Decentralized, declarative workflows
Policy Management
Policy management at the edge.
Self-Service Control
Self-service control and flexibility over edge proxy needs, eliminating manual tasks.
World-Class Support
Professional world-class support on Enterprise plans.
Service Mesh
Service Mesh Integrations: multi-cluster support, rate limiting, automatic HTTPS, custom request filters
No Hidden Fees - High ROI
Cost Effective Solution
Edge Stack API Gateway offers cost-effective solutions without the hidden fees of plugins or extra infrastructure. It's ready to use without requiring a Postgres Database or additional plugin purchases.
Achieve Greater ROI
Edge Stack API Gateway offers cost-effective solutions without the hidden fees of plugins or extra infrastructure. It's ready to use without requiring a Postgres Database or additional plugin purchases.
Security and authentication at the edge
Edge Stack, the Kubernetes-native API Gateway, makes securing microservices easy with a comprehensive set of advanced functionality, including automatic TLS, comprehensive authentication options (OAuth2, OIDC, JWT, Single Sign On, and more), rate limiting, IP allow/deny listing, WAF integration, and fine-grained access control.
Schedule a Demo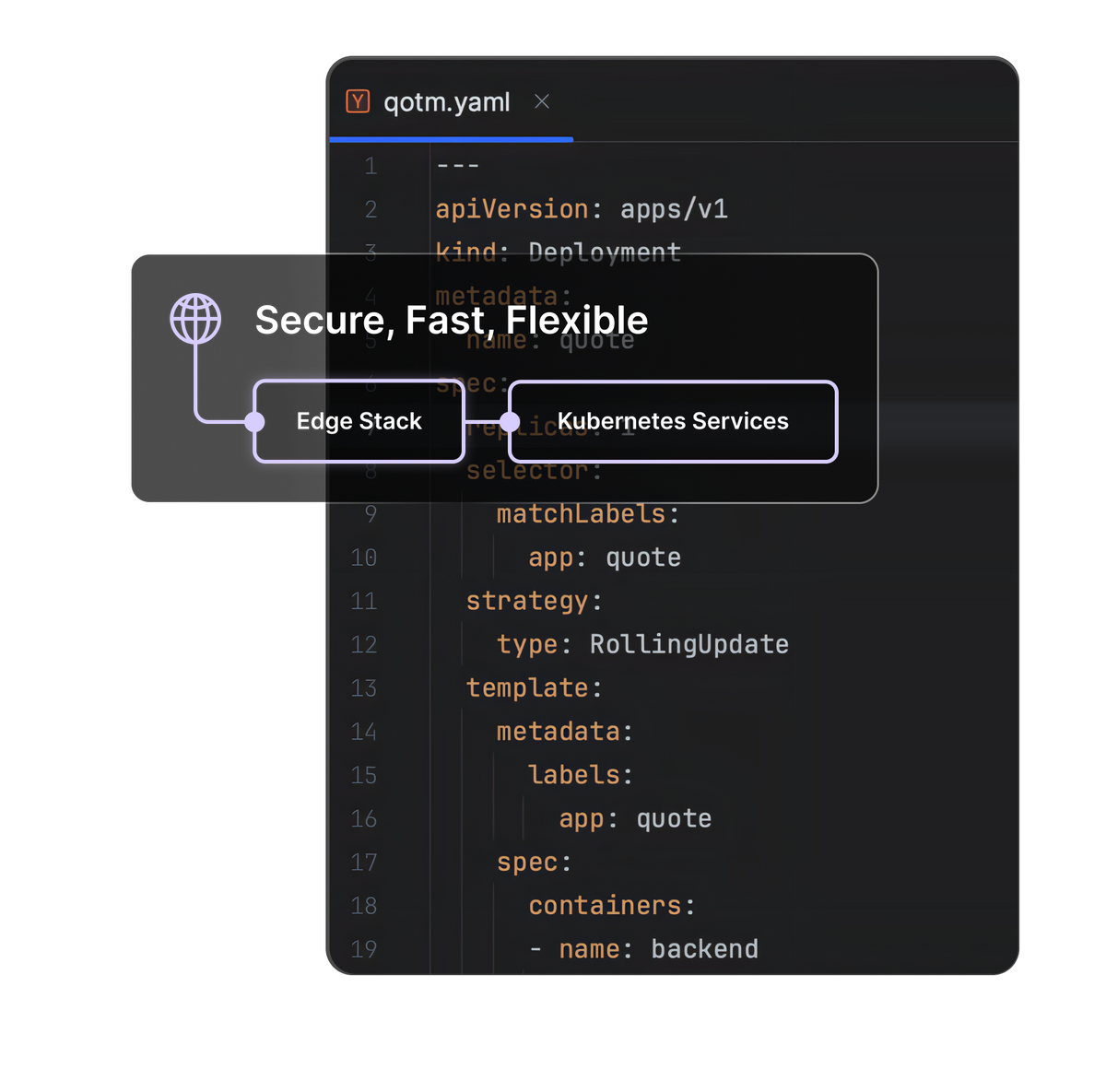
How Edge Stack works
Edge Stack Kubernetes-native API Gateway plays an important role throughout the entire microservices lifecycle and can make a difference to your organization's design, development, testing, deployment and observability activities.
Kubernetes ingress controller
Routing user requests into your Kubernetes cluster requires a modern traffic management solution. Edge Stack API Gateway provides a robust Kubernetes Ingress Controller that supports a broad range of protocols, including TCP, HTTP/1/2/3 and gRPC, supports TLS and mTLS termination, and provides reliability and resilience features to protect your backend services.
- Designed and built with Kubernetes best practices
- Cross-Origin Resource Sharing (CORS)
- TLS and mTLS
- Automatic HTTPS
- Robust configuration options
- Enabled for developer self-service

Simplified traffic management
Edge Stack includes support for automatic retries, timeouts, circuit breakers, and rate limiting to maximize application availability. In addition to keeping your application available, Edge Stack supports progressive releases with fine-grained traffic management controls.
- Advanced load balancing
- Timeouts, retries, and circuit breaking
- Progressive delivery and continuous delivery support
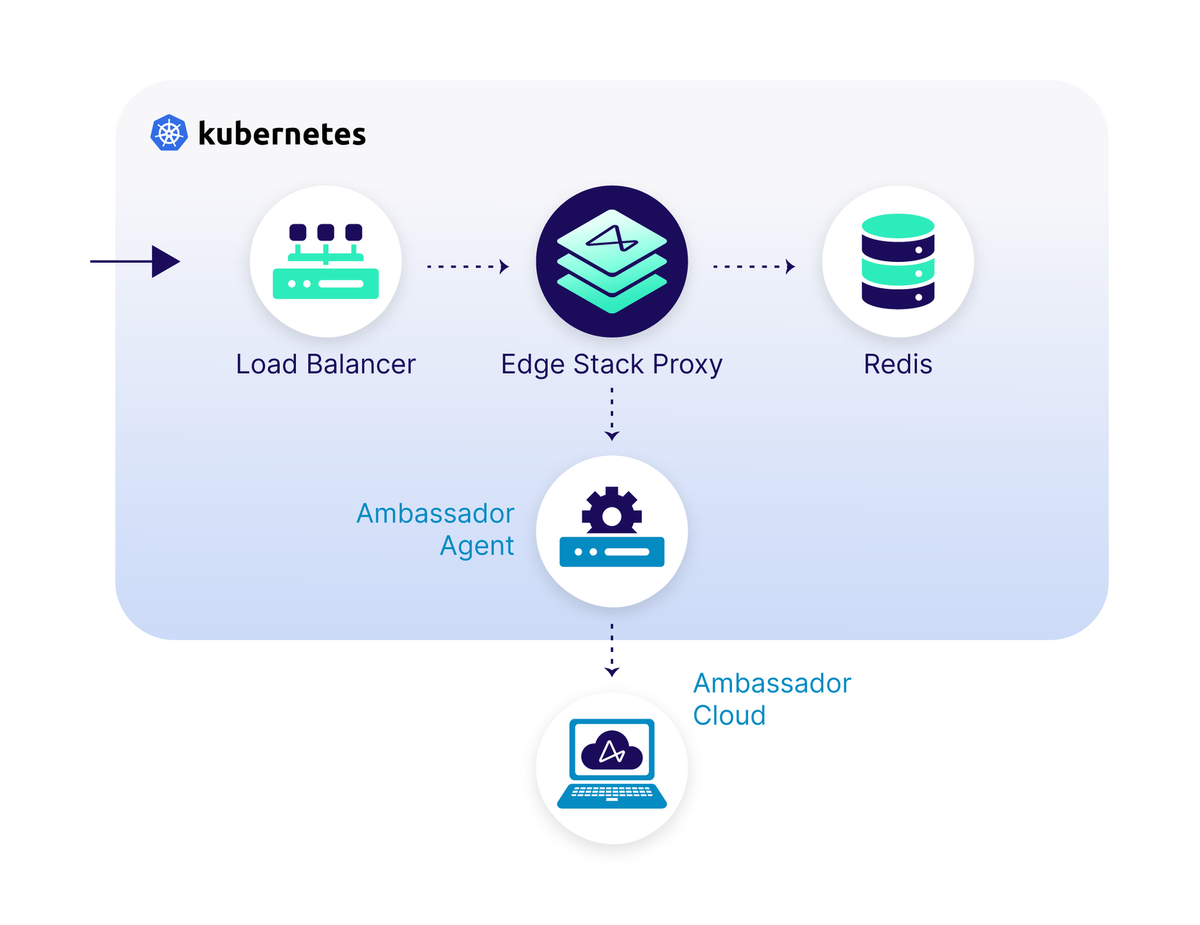
Decentralized, declarative workflow
Edge Stack empowers development teams to safely manage their ingress, using the same workflow you already use with K8s.
- Configure using K8s Custom Resource Definitions
- Operator-focused CRDs (host, listener, & security configuration)
- Developer-focused CRDs (mappings & rate limiting configuration)
- Protocol support, including TCP, HTTP/1, HTTP/2, HTTP/3, and gRPC & gRPC-Web
- Zero-downtime reconfiguration
- Integrate with existing GitOps / Kubernetes workflows

Ready to learn more?
Edge Stack API Gateway Integrations
Seamless Integration with Your Tech Stack Explore the Complete List of Integrations for Edge Stack Kubernetes API Gateway
Prometheus
A popular monitoring solution, Prometheus can scrape metrics from Edge Stack, allowing users to monitor the health and performance of their ingress and services, and set up alerts for any anomalies.

New Relic
This performance management solution integrates with Edge Stack to offer in-depth application monitoring. By combining NewRelic’s analytics with Edge Stack's ingress capabilities, users can get comprehensive insights into their application stack.

DataDog
A cloud-scale monitoring service, DataDog's integration with Edge Stack provides real-time metrics, traces, and logs to help teams monitor and optimize their infrastructure and application performance.

Splunk
Splunk offers operational intelligence by analyzing big data. When integrated with Edge Stack, it can process vast amounts of event data to provide actionable insights.
See Edge Stack in Action
See why Edge Stack is the chosen Kubernetes-native API Gateway solution for development and platform teams alike — and what it can do for your team.