SRE vs. Platform Engineering



DevOps, GitOps, and the Rise of Cloud-Native Engineering

Over the past decade, engineering and technology organizations have converged on a common set of best practices for building and deploying cloud-native applications. These best practices include continuous delivery, containerization, and building observable systems.
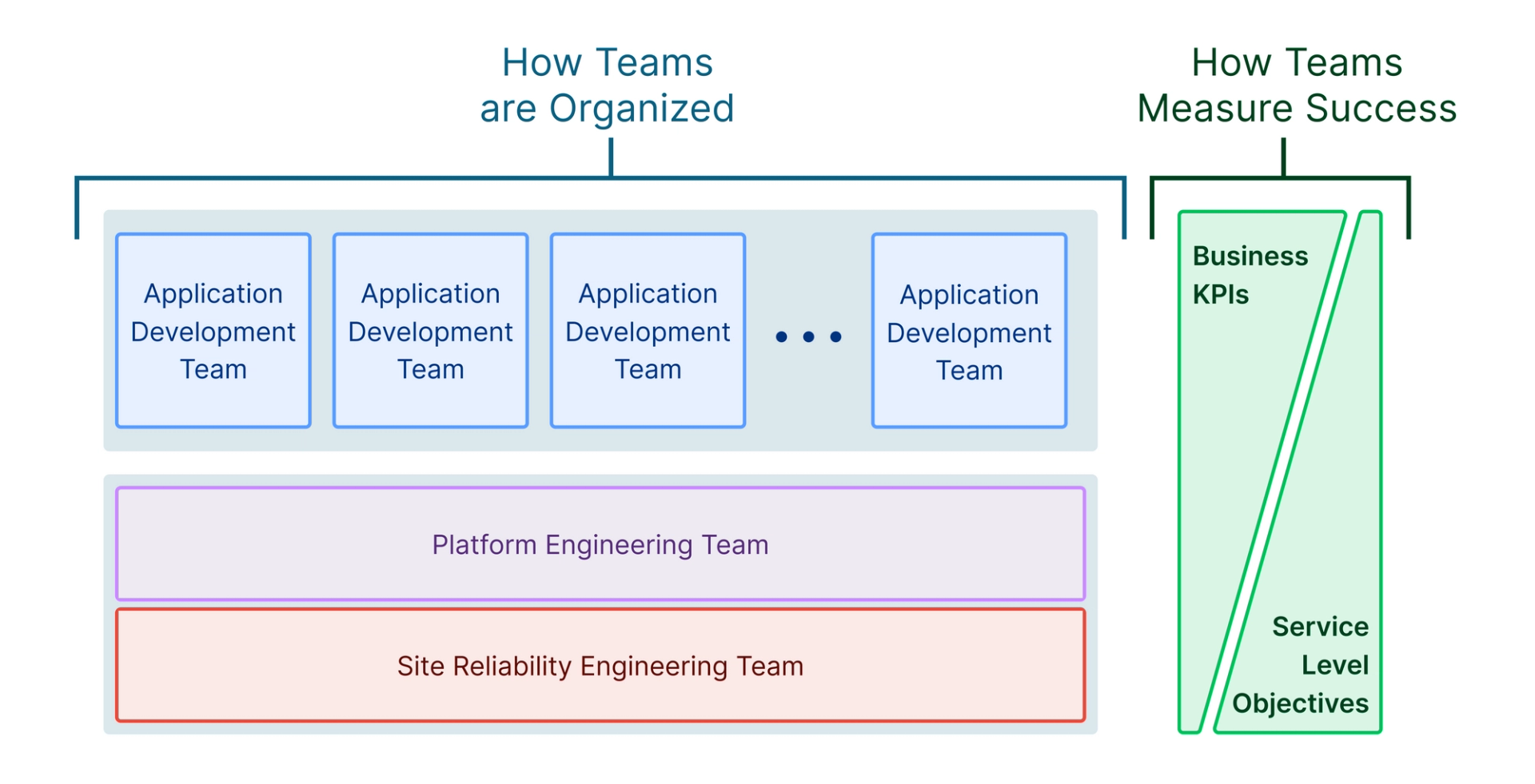
At the same time, cloud-native organizations have radically changed how they’re organized, moving from large departments (development, QA, operations, release) to smaller, independent development teams. These application development teams are supported by two new functions: site reliability engineering and platform engineering. SRE and platform engineering are spiritual successor of traditional operations teams, and bring the discipline of software engineering to different aspects of operations.
Site Reliability Engineering and Platform Engineering
Platform engineering teams apply software engineering principles to accelerate software delivery. Platform engineers ensure application development teams are productive in all aspects of the software delivery lifecycle.
Site reliability engineering teams apply software engineering principles to improve reliability. Site reliability engineers minimize the frequency and impact of failures that can impact the overall reliability of a cloud application.
These two teams are frequently confused and the terms are sometimes used interchangeably. Indeed, some organizations consolidate SRE and platform engineering into the same function. This occurs because both roles apply a common set of principles:
- Platform as product. These teams should spend time understanding their internal customers, building roadmaps, having a planned release cadence, writing documentation, and doing all the things that go into a software product.
- Self-service platforms. These teams build their platforms for internal use. In these platforms, best practices are encoded, so that the users of these platforms don’t need to worry about it -- they just push the button. In the Puppet Labs 2020 State of DevOps report, Puppet Labs found that High functioning DevOps organizations had more self-service infrastructure than low DevOps evolution organizations.
- A constant focus on eliminating toil. As defined in the Google SRE book, toil is manual, repetitive, automatable, tactical work. The best SRE and platform teams identify toil, and work to eliminate it.
Platform Engineering
Platform engineers constantly examine the entire software development lifecycle from source to production. From this introspective process, they build a workflow that enables application developers to rapidly code and ship software. A basic workflow typically includes a source control system connected with a continuous integration system, along with a way to deploy artifacts into production.
As the number of application developers using the workflow grows, the needs of the platform evolves. Different teams of application developers need similar but different workflows, so self-service infrastructure becomes important. Common platform engineering targets for self-service include CI/CD, alerting, and deployment workflows.
In addition to self-service, education and collaboration become challenges. Platform engineers find they increasingly spend time educating application developers on best practices and how to best use the platform. Application developers also find that they depend on other teams of application developers, and look to the platform engineering team to give them the tools to collaborate productively with different teams.
Site Reliability Engineering
Site reliability engineers create and evolve systems to automatically run applications, reliably. The concept of site reliability engineering originated at Google, and is documented in detail in the Google SRE Book. Ben Treynor Sloss, the SVP at Google responsible for technical operations, described SRE as “what happens when you ask a software engineer to design an operations team.”
SREs define service level objectives and build systems to help services achieve these objectives. These systems evolve into a platform and workflow that encompass monitoring, incident management, eliminating single points of failure, failure mitigation, and more.
A key part of SRE culture is to treat every failure as a failure in the reliability system. Rigorous post-mortems are critical to identifying the root cause of the failure, and corrective actions are introduced into the automatic system to continue to improve reliability.
SRE and Platform Engineering at New Relic
One of us (Bjorn Freeman-Benson) managed the engineering organization at New Relic until 2015 as it grew from a handful of customers to tens of thousands of customers, all sending millions of requests per second into the cloud. New Relic had independent SRE and platform engineering teams that followed the general principles outlined above.
One of the reasons these teams were built separately was that the people who thrived in these roles differed. While both SREs and platform engineers need strong systems engineering skills in addition to classic programming skills, the roles dictate very different personality types. SREs tend to enjoy crisis management and get an adrenaline rush out of troubleshooting an outage. SRE managers thrive under intense pressure and are good at recruiting and managing similarly minded folks. On the other hand, platform engineers are more typical software engineers, preferring to work without interruption on big, complex problems. Platform engineering managers prefer to operate on a consistent cadence.
DevOps and GitOps
Over the past decade, DevOps has become a popular term to describe many of these practices. More recently, GitOps has also emerged as a popular term. How do DevOps and GitOps relate to platform and SRE teams?
Both DevOps and GitOps are a loosely codified set of principles of how to manage different aspects of infrastructure. The core principles of both of these philosophies -- automation, infrastructure as code, application of software engineering -- are very similar.
DevOps is a broad movement that began with a focus on eliminating traditional silos between development and operation. Over time, strategies such as infrastructure automation and engineering applications with operations in mind have gained widespread acceptance as ways better build highly reliable applications.
GitOps is an approach for application delivery. In GitOps, declarative configuration is used to codify the desired state of the application at any moment in time. This configuration is managed in a versioned source control system as the single source of truth. This ensures auditability, reproducibility, and consistency of configuration.
In short: DevOps is a set of guiding principles for SRE, while GitOps is a set of guiding principles for platform engineering.
Unlocking application development productivity
Site reliability engineering and platform engineering are two functions that are critical to optimizing engineering organizations for building cloud-native applications. The SRE team works to deliver infrastructure for highly reliable applications, while the platform engineering team works to deliver infrastructure for rapid application development. Together, these two teams unlock the productivity of application development teams.
Related: The Developer Experience and the Role of the SRE Are Changing, Here’s How